本次实践使用方法:
ch_PP-OCRv3_det_student.yml 文件配置详解:
Global:
debug: false
use_gpu: true
epoch_num: 50
log_smooth_window: 20
print_batch_step: 5
save_model_dir: ./output/ch_PP-OCR_V3_det/
save_epoch_step: 50
eval_batch_step:
- 0
- 50
cal_metric_during_train: false
pretrained_model: https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
checkpoints: null
save_inference_dir: null
use_visualdl: false
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./checkpoints/det_db/predicts_db.txt
distributed: true
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: True
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 2
regularizer:
name: L2
factor: 5.0e-05
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- IaaAugment:
augmenter_args:
- type: Fliplr
args:
p: 0.5
- type: Affine
args:
rotate:
- -10
- 10
- type: Resize
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 960
- 960
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 8
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- DetResizeForTest: null
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- shape
- polys
- ignore_tags
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2验证初始 student 模型。
PS E:\LEARN\Project-all\AI\PaddleOCR-main> & E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe e:/LEARN/Project-all/AI/PaddleOCR-main/tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt]
[2024/12/09 16:00:51] ppocr INFO: Architecture :
[2024/12/09 16:00:51] ppocr INFO: Backbone :
[2024/12/09 16:00:51] ppocr INFO: disable_se : True
[2024/12/09 16:00:51] ppocr INFO: model_name : large
[2024/12/09 16:00:51] ppocr INFO: name : MobileNetV3
[2024/12/09 16:00:51] ppocr INFO: scale : 0.5
[2024/12/09 16:00:51] ppocr INFO: Head :
[2024/12/09 16:00:51] ppocr INFO: k : 50
[2024/12/09 16:00:51] ppocr INFO: name : DBHead
[2024/12/09 16:00:51] ppocr INFO: Neck :
[2024/12/09 16:00:51] ppocr INFO: name : RSEFPN
[2024/12/09 16:00:51] ppocr INFO: out_channels : 96
[2024/12/09 16:00:51] ppocr INFO: shortcut : True
[2024/12/09 16:00:51] ppocr INFO: Transform : None
[2024/12/09 16:00:51] ppocr INFO: algorithm : DB
[2024/12/09 16:00:51] ppocr INFO: model_type : det
[2024/12/09 16:00:51] ppocr INFO: Eval :
[2024/12/09 16:00:51] ppocr INFO: dataset :
[2024/12/09 16:00:51] ppocr INFO: data_dir : E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green
[2024/12/09 16:00:51] ppocr INFO: label_file_list : ['E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt']
[2024/12/09 16:00:51] ppocr INFO: name : SimpleDataSet
[2024/12/09 16:00:51] ppocr INFO: transforms :
[2024/12/09 16:00:51] ppocr INFO: DecodeImage :
[2024/12/09 16:00:51] ppocr INFO: channel_first : False
[2024/12/09 16:00:51] ppocr INFO: img_mode : BGR
[2024/12/09 16:00:51] ppocr INFO: DetLabelEncode : None
[2024/12/09 16:00:51] ppocr INFO: DetResizeForTest : None
[2024/12/09 16:00:51] ppocr INFO: NormalizeImage :
[2024/12/09 16:00:51] ppocr INFO: mean : [0.485, 0.456, 0.406]
[2024/12/09 16:00:51] ppocr INFO: order : hwc
[2024/12/09 16:00:51] ppocr INFO: scale : 1./255.
[2024/12/09 16:00:51] ppocr INFO: std : [0.229, 0.224, 0.225]
[2024/12/09 16:00:51] ppocr INFO: ToCHWImage : None
[2024/12/09 16:00:51] ppocr INFO: KeepKeys :
[2024/12/09 16:00:51] ppocr INFO: keep_keys : ['image', 'shape', 'polys', 'ignore_tags']
[2024/12/09 16:00:51] ppocr INFO: loader :
[2024/12/09 16:00:51] ppocr INFO: batch_size_per_card : 1
[2024/12/09 16:00:51] ppocr INFO: drop_last : False
[2024/12/09 16:00:51] ppocr INFO: num_workers : 2
[2024/12/09 16:00:51] ppocr INFO: shuffle : False
[2024/12/09 16:00:51] ppocr INFO: Global :
[2024/12/09 16:00:51] ppocr INFO: cal_metric_during_train : False
[2024/12/09 16:00:51] ppocr INFO: checkpoints : None
[2024/12/09 16:00:51] ppocr INFO: debug : False
[2024/12/09 16:00:51] ppocr INFO: distributed : False
[2024/12/09 16:00:51] ppocr INFO: epoch_num : 500
[2024/12/09 16:00:51] ppocr INFO: eval_batch_step : [0, 400]
[2024/12/09 16:00:51] ppocr INFO: infer_img : doc/imgs_en/img_10.jpg
[2024/12/09 16:00:51] ppocr INFO: log_smooth_window : 20
[2024/12/09 16:00:51] ppocr INFO: pretrained_model : models/ch_PP-OCRv3_det_distill_train/student.pdparams[2024/12/09 16:00:51] ppocr INFO: print_batch_step : 10
[2024/12/09 16:00:51] ppocr INFO: save_epoch_step : 100
[2024/12/09 16:00:51] ppocr INFO: save_inference_dir : None
[2024/12/09 16:00:51] ppocr INFO: save_model_dir : ./output/ch_PP-OCR_V3_det/
[2024/12/09 16:00:51] ppocr INFO: save_res_path : ./checkpoints/det_db/predicts_db.txt
[2024/12/09 16:00:51] ppocr INFO: use_gpu : True
[2024/12/09 16:00:51] ppocr INFO: use_visualdl : False
[2024/12/09 16:00:51] ppocr INFO: Loss :
[2024/12/09 16:00:51] ppocr INFO: alpha : 5
[2024/12/09 16:00:51] ppocr INFO: balance_loss : True
[2024/12/09 16:00:51] ppocr INFO: beta : 10
[2024/12/09 16:00:51] ppocr INFO: main_loss_type : DiceLoss
[2024/12/09 16:00:51] ppocr INFO: name : DBLoss
[2024/12/09 16:00:51] ppocr INFO: ohem_ratio : 3
[2024/12/09 16:00:51] ppocr INFO: Metric :
[2024/12/09 16:00:51] ppocr INFO: main_indicator : hmean
[2024/12/09 16:00:51] ppocr INFO: name : DetMetric
[2024/12/09 16:00:51] ppocr INFO: Optimizer :
[2024/12/09 16:00:51] ppocr INFO: beta1 : 0.9
[2024/12/09 16:00:51] ppocr INFO: beta2 : 0.999
[2024/12/09 16:00:51] ppocr INFO: lr :
[2024/12/09 16:00:51] ppocr INFO: learning_rate : 0.001
[2024/12/09 16:00:51] ppocr INFO: name : Cosine
[2024/12/09 16:00:51] ppocr INFO: warmup_epoch : 2
[2024/12/09 16:00:51] ppocr INFO: name : Adam
[2024/12/09 16:00:51] ppocr INFO: regularizer :
[2024/12/09 16:00:51] ppocr INFO: factor : 5e-05
[2024/12/09 16:00:51] ppocr INFO: name : L2
[2024/12/09 16:00:51] ppocr INFO: PostProcess :
[2024/12/09 16:00:51] ppocr INFO: box_thresh : 0.6
[2024/12/09 16:00:51] ppocr INFO: max_candidates : 1000
[2024/12/09 16:00:51] ppocr INFO: name : DBPostProcess
[2024/12/09 16:00:51] ppocr INFO: thresh : 0.3
[2024/12/09 16:00:51] ppocr INFO: unclip_ratio : 1.5
[2024/12/09 16:00:51] ppocr INFO: Train :
[2024/12/09 16:00:51] ppocr INFO: dataset :
[2024/12/09 16:00:51] ppocr INFO: data_dir : ./train_data/icdar2015/text_localization/
[2024/12/09 16:00:51] ppocr INFO: label_file_list : ['./train_data/icdar2015/text_localization/train_icdar2015_label.txt']
[2024/12/09 16:00:51] ppocr INFO: name : SimpleDataSet
[2024/12/09 16:00:51] ppocr INFO: ratio_list : [1.0]
[2024/12/09 16:00:51] ppocr INFO: transforms :
[2024/12/09 16:00:51] ppocr INFO: DecodeImage :
[2024/12/09 16:00:51] ppocr INFO: channel_first : False
[2024/12/09 16:00:51] ppocr INFO: img_mode : BGR
[2024/12/09 16:00:51] ppocr INFO: DetLabelEncode : None
[2024/12/09 16:00:51] ppocr INFO: IaaAugment :
[2024/12/09 16:00:51] ppocr INFO: augmenter_args :
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: p : 0.5
[2024/12/09 16:00:51] ppocr INFO: type : Fliplr
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: rotate : [-10, 10]
[2024/12/09 16:00:51] ppocr INFO: type : Affine
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: size : [0.5, 3]
[2024/12/09 16:00:51] ppocr INFO: type : Resize
[2024/12/09 16:00:51] ppocr INFO: EastRandomCropData :
[2024/12/09 16:00:51] ppocr INFO: keep_ratio : True
[2024/12/09 16:00:51] ppocr INFO: max_tries : 50
[2024/12/09 16:00:51] ppocr INFO: size : [960, 960]
[2024/12/09 16:00:51] ppocr INFO: MakeBorderMap :
[2024/12/09 16:00:51] ppocr INFO: shrink_ratio : 0.4
[2024/12/09 16:00:51] ppocr INFO: thresh_max : 0.7
[2024/12/09 16:00:51] ppocr INFO: thresh_min : 0.3
[2024/12/09 16:00:51] ppocr INFO: MakeShrinkMap :
[2024/12/09 16:00:51] ppocr INFO: min_text_size : 8
[2024/12/09 16:00:51] ppocr INFO: shrink_ratio : 0.4
[2024/12/09 16:00:51] ppocr INFO: NormalizeImage :
[2024/12/09 16:00:51] ppocr INFO: mean : [0.485, 0.456, 0.406]
[2024/12/09 16:00:51] ppocr INFO: order : hwc
[2024/12/09 16:00:51] ppocr INFO: scale : 1./255.
[2024/12/09 16:00:51] ppocr INFO: std : [0.229, 0.224, 0.225]
[2024/12/09 16:00:51] ppocr INFO: ToCHWImage : None
[2024/12/09 16:00:51] ppocr INFO: KeepKeys :
[2024/12/09 16:00:51] ppocr INFO: keep_keys : ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask']
[2024/12/09 16:00:51] ppocr INFO: loader :
[2024/12/09 16:00:51] ppocr INFO: batch_size_per_card : 8
[2024/12/09 16:00:51] ppocr INFO: drop_last : False
[2024/12/09 16:00:51] ppocr INFO: num_workers : 4
[2024/12/09 16:00:51] ppocr INFO: shuffle : True
[2024/12/09 16:00:51] ppocr INFO: profiler_options : None
[2024/12/09 16:00:51] ppocr INFO: train with paddle 2.6.0 and device Place(gpu:0)
[2024/12/09 16:00:51] ppocr INFO: Initialize indexs of datasets:['E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt']
W1209 16:00:51.662034 53304 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver
API Version: 12.4, Runtime API Version: 11.7
W1209 16:00:51.667035 53304 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
[2024/12/09 16:00:52] ppocr INFO: load pretrain successful from models/ch_PP-OCRv3_det_distill_train/student
[2024/12/09 16:00:52] ppocr INFO: metric in ckpt ***************
[2024/12/09 16:00:52] ppocr INFO: is_float16:False
eval model:: 100%|██████████████████████████████████████████████████████▉| 5005/5006 [03:48<00:00, 21.88it/s]
[2024/12/09 16:04:41] ppocr INFO: metric eval ***************
[2024/12/09 16:04:41] ppocr INFO: precision:0.6304547241514874
[2024/12/09 16:04:41] ppocr INFO: recall:0.9614308553157475
[2024/12/09 16:04:41] ppocr INFO: hmean:0.7615354174910962
[2024/12/09 16:04:41] ppocr INFO: fps:42.52257374304988发现单纯使用预训练模型 student. Pdparams 在数据集上进行评估得到的 hmean 仅仅是
所以针对这个模型要在我们的数据集上进行 fine-tune。
在使用预训练模型进行 fine-tune 时,需要设置如下 11 个字段
- Global. Pretrained_model: 指向 PP-OCRv 3 文本检测预训练模型地址
- Global. Eval_batch_step: 模型多少 step 评估一次,这里设为从第 0 个 step 开始没隔 772 个 step 评估一次,772 为一个 epoch 总的 step 数。
- Optimizer. Lr. Name: 学习率衰减器设为常量 Const
- Optimizer. Lr. Learning_rate: 学习率设为之前的 0.05 倍
- Optimizer. Lr. Warmup_epoch: warmup_epoch 设为 0
- Train. Dataset. Data_dir:指向训练集图片存放目录
- Train. Dataset. Label_file_list:指向训练集标注文件
- Eval. Dataset. Data_dir:指向验证集图片存放目录
- Eval. Dataset. Label_file_list:指向验证集标注文件
- Eval. Loader. Num_workers: 验证集多进程数据读取的进程数,在 aistudio 中需要设为 0
具体使用代码如下:
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams Global.save_model_dir=output/CCPD/det/ Global.eval_batch_step="[0, 772]" Optimizer.lr.name=Cosine Optimizer.lr.learning_rate=0.0005 Train.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Train.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/train/det.txt] Train.loader.num_workers=1 Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt] Eval.loader.num_workers=0验证训练出来的模型
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.checkpoints=output/CCPD/det/best_accuracy.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt]文字识别
学习率衰减器
NOTE
学习率衰减是一个非常有效的炼丹技巧之一,在神经网络的训练过程中,当accuracy出现震荡或loss不再下降时,进行适当的学习率衰减是一个行之有效的手段,很多时候能明显提高accuracy。
在针对 Optimizer.lr.name 中,通过查看 PaddleOCR 的文档,其支持以下几种学习率衰减器:
Simple Momentum optimizer :具有速度状态的简单动量优化器。 Learning_rate (浮点数|变量) - 用于更新参数的学习率。 可以是浮点数或以一个浮点数作为数据元素的变量。 动量 (浮点数) - 动量因子。 正则化 (WeightDecayRegularizer,可选) - 正则化的策略。
Adm :Adm本质上是带有动量项的RMSProp,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使参数比较稳定。 Adam是一种学习速率自适应的深度神经网络方法,他利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
RMSProp:RMSProp算法通过修改AdaGrad得来,其目的是在非凸背景下效果更好。针对梯度平方和累计越来越大的问题,RMSProp指数加权的移动平均代替梯度平方和。RMSProp为了使用移动平均,还引入了一个新的超参数
,用来控制移动平均的长度范围。 均方根传播 (RMSProp) 是一种未公开的自适应学习率方法。 参数:learning_rate (float|Variable) - 用于更新参数的学习率。 可以是浮点值或带有一个浮点值作为数据元素的变量。 动量 (float) - 动量因子。 Rho (float) - 方程中的 rho 值。 Epsilon (float) - 避免除以零,默认值为 1 e-6。 正则化 (WeightDecayRegularizer,可选) - 正则化的策略。
Adadelta:Adadelta 是一种自适应学习率方法,是 AdaGrad 的扩展,建立在 AdaGrad 的基础上,旨在减少其过激的、单调递减的学习率。Adadelta 不是积累所有过去的平方梯度,而是将积累的过去梯度的窗口限制为某个固定大小。 将Adadelta理解为AdaGrad和RMSProp算法的扩展。Adadelta是RMSProp的进一步扩展,旨在提高算法的收敛性并消除对手动指定初始学习率的需要。 与RMSProp一样,Adadelta为每个参数计算平方偏导数的衰减移动平均值。关键区别在于使用delta的衰减平均值或参数变化来计算参数的步长。
Adamw:AdamW其实是在Adam的基础上加入了weight decay正则化。 AdamW和Adam唯一的区别,就是weight decay的加入方式。 在Adam当中,weight decay是直接加入到梯度当中:
其中
是当前 step 的梯度, 是上一个 step 中的模型权重, 是正则化系数。 而在 AdamW 中,正则化变成了: 其中
是学习率。 所以 AdamW 的思路就是直接在权重上进行衰减吗,在收敛速度上也领先于 Adam。
在此链接 中,对比了一些优化器
示例一:
示例二:
示例三:
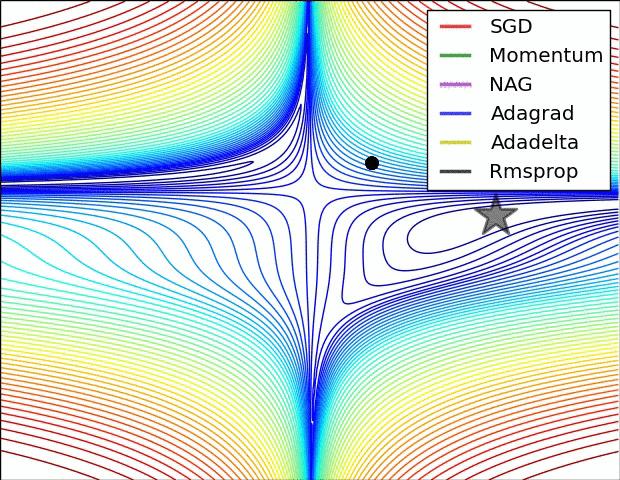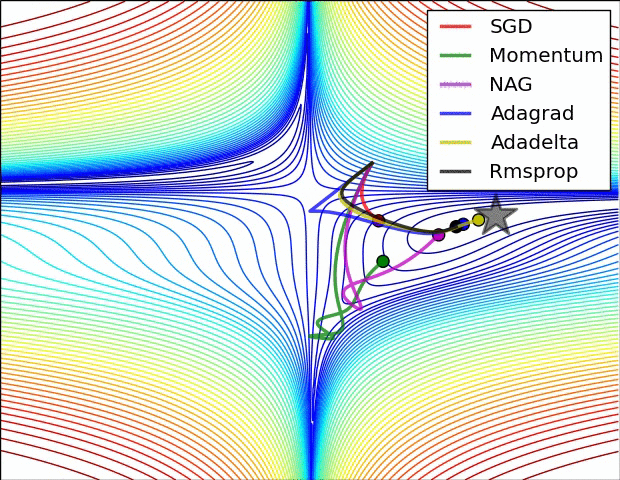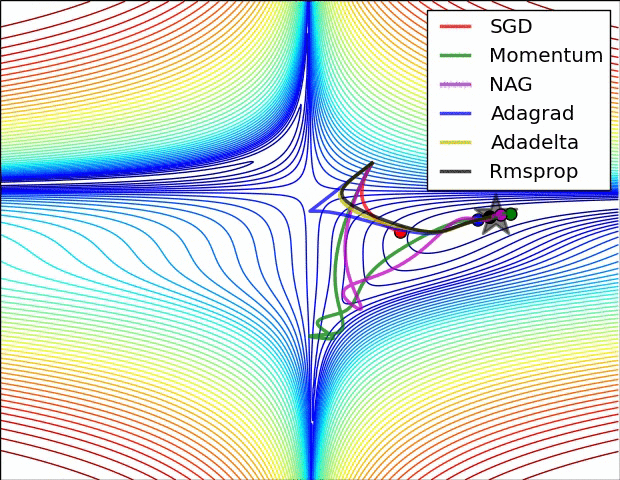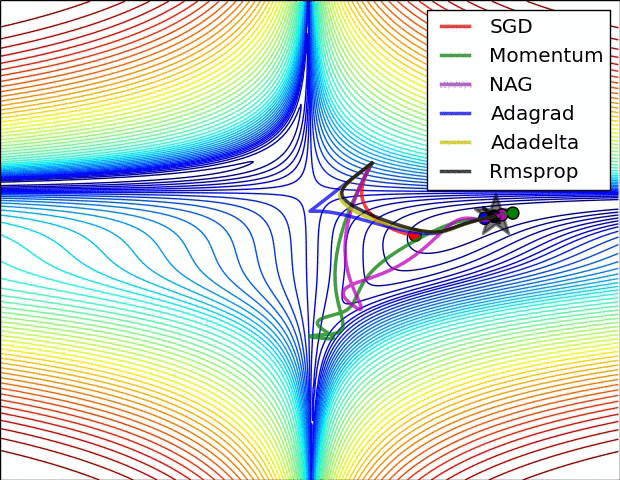
文本检测的难点
文本的多样性(颜色、大小、字体、形状、方向、语言、文本长度等)
复制的背景和干扰(图像失真、模糊、低分辨率、阴影、高度等)
富集文本、重叠文本
文字存在局部一致性,即文本行的一部分也可能视为独立的文本。
综上所述,在文本检测方面,可能会出现文本漏检和污染检测等问题。
两大主流方法
基于回归的方法
基于回归的方法类似于目标检测,比如由 SSD 演化而来的 TextBox,以及基于 FastRCNN 的 CTPN。
但是,这部分的缺点是对于弯曲的文本,难以得到平滑的包围线,并且模型比较复杂,在性能上没有什么优势。
基于分割的方法
基于分割的方法是做像素层面的分类,判断每一个像素是否属于一个文本目标,得到文本区域的概率图之后,通过后处理得到文本分割区域的包围曲线。
PPOCR 全流程
数据集
数据集来自于 CCPD 2020 新能源车牌数据集,该数据集分布如下:
| 数据集类型 | 数量 |
|---|---|
| 训练集 | 5769 |
| 验证集 | 1001 |
| 测试集 | 5006 |
数据集图片实例如下:

CPPD的图片文件名具有特殊规则,详细可查看:https://github.com/detectRecog/CCPD
具体规则如下:
例如: 025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
每个名称可以分为七个字段,以-符号作为分割。这些字段解释如下。
025:车牌面积与整个图片区域的面积比。025 (25%)
95_113:水平倾斜程度和垂直倾斜度。水平 95度 垂直 113度
154&383_386&473:左上和右下顶点的坐标。左上(154,383) 右下(386,473)
386&473_177&454_154&383_363&402:整个图像中车牌的四个顶点的精确(x,y)坐标。这些坐标从右下角顶点开始。(386,473) (177,454) (154,383) (363,402)
0_0_22_27_27_33_16:CCPD中的每个图像只有一个车牌。每个车牌号码由一个汉字,一个字母和五个字母或数字组成。有效的中文车牌由七个字符组成:省(1个字符),字母(1个字符),字母+数字(5个字符)。“ 0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O,而不是数字0。我们将O用作“无字符”的符号,因为中文车牌字符中没有O。因此以上车牌拼起来即为 皖AY339S
37:牌照区域的亮度。 37 (37%)
15:车牌区域的模糊度。15 (15%)
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W','X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']在开始训练之前,可使用如下代码制作符合PP-OCR训练格式的标注文件。同时对数据集进行展示。
import cv2
import os
import json
from tqdm import tqdm
import numpy as np
from matplotlib import pyplot as plt
provinces = [
"皖",
"沪",
"津",
"渝",
"冀",
"晋",
"蒙",
"辽",
"吉",
"黑",
"苏",
"浙",
"京",
"闽",
"赣",
"鲁",
"豫",
"鄂",
"湘",
"粤",
"桂",
"琼",
"川",
"贵",
"云",
"藏",
"陕",
"甘",
"青",
"宁",
"新",
"警",
"学",
"O",
]
alphabets = [
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"J",
"K",
"L",
"M",
"N",
"P",
"Q",
"R",
"S",
"T",
"U",
"V",
"W",
"X",
"Y",
"Z",
"O",
]
ads = [
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"J",
"K",
"L",
"M",
"N",
"P",
"Q",
"R",
"S",
"T",
"U",
"V",
"W",
"X",
"Y",
"Z",
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
"O",
]
def make_label(img_dir, save_gt_folder, phase):
crop_img_save_dir = os.path.join(save_gt_folder, phase, "crop_imgs")
os.makedirs(crop_img_save_dir, exist_ok=True)
f_det = open(os.path.join(save_gt_folder, phase, "det.txt"), "w", encoding="utf-8")
f_rec = open(os.path.join(save_gt_folder, phase, "rec.txt"), "w", encoding="utf-8")
for filename in tqdm(os.listdir(os.path.join(img_dir, phase))):
str_list = filename.split("-")
coord_list = str_list[3].split("_")
txt_list = str_list[4].split("_")
boxes = []
for coord in coord_list:
boxes.append([int(x) for x in coord.split("&")])
boxes = [boxes[2], boxes[3], boxes[0], boxes[1]]
lp_number = (
provinces[int(txt_list[0])]
+ alphabets[int(txt_list[1])]
+ "".join([ads[int(x)] for x in txt_list[2:]])
)
# det
det_info = [{"points": boxes, "transcription": lp_number}]
f_det.write(
"{}\t{}\n".format(
os.path.join(phase, filename), json.dumps(det_info, ensure_ascii=False)
)
)
# rec
boxes = np.float32(boxes)
img = cv2.imread(os.path.join(img_dir, phase, filename))
# crop_img = img[int(boxes[:,1].min()):int(boxes[:,1].max()),int(boxes[:,0].min()):int(boxes[:,0].max())]
crop_img = get_rotate_crop_image(img, boxes)
crop_img_save_filename = "{}.jpg".format("_".join(txt_list))
crop_img_save_path = os.path.join(crop_img_save_dir, crop_img_save_filename)
cv2.imwrite(crop_img_save_path, crop_img)
f_rec.write(
"{}/crop_imgs/{}\t{}\n".format(phase, crop_img_save_filename, lp_number)
)
f_det.close()
f_rec.close()
def get_rotate_crop_image(img, points):
"""
img_height, img_width = img.shape[0:2]
left = int(np.min(points[:, 0]))
right = int(np.max(points[:, 0]))
top = int(np.min(points[:, 1]))
bottom = int(np.max(points[:, 1]))
img_crop = img[top:bottom, left:right, :].copy()
points[:, 0] = points[:, 0] - left
points[:, 1] = points[:, 1] - top
"""
assert len(points) == 4, "shape of points must be 4*2"
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]), np.linalg.norm(points[2] - points[3])
)
)
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]), np.linalg.norm(points[1] - points[2])
)
)
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height],
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC,
)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def show_ppocr_det_label(img_dir, label_path):
i = 0
print("{0} show det {0}".format("*" * 10))
with open(label_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# parse
line = line.strip().split("\t")
img_path = os.path.join(img_dir, line[0])
label_list = json.loads(line[1])
print(line[0], label_list)
# show
img = cv2.imread(img_path)
for label in label_list:
cv2.polylines(
img,
[np.array(label["points"])],
True,
color=(0, 0, 255),
thickness=2,
)
plt.figure(figsize=(10, 8))
plt.imshow(img[:, :, ::-1])
plt.show()
i += 1
if i > 3:
break
def show_ppocr_rec_label(img_dir, label_path):
i = 0
print("{0} show rec {0}".format("*" * 10))
with open(label_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# parse
line = line.strip().split("\t")
img_path = os.path.join(img_dir, line[0])
label = line[1]
print(line[0], label)
# show
img = cv2.imread(img_path)
plt.figure(figsize=(10, 8))
plt.imshow(img[:, :, ::-1])
plt.show()
i += 1
if i > 3:
break
img_dir = R"E:\LEARN\Project-all\AI\PaddleOCR-main\Data\CCPD2020\ccpd_green"
save_gt_folder = (
R"E:\LEARN\Project-all\AI\PaddleOCR-main\Data\CCPD2020\ccpd_green\PPOCR"
)
# phase = 'train' # change to val and test to make val dataset and test dataset
for phase in ["train", "val", "test"]:
make_label(img_dir, save_gt_folder, phase)
show_ppocr_det_label(img_dir, os.path.join(save_gt_folder, "train", "det.txt"))
show_ppocr_rec_label(save_gt_folder, os.path.join(save_gt_folder, "train", "rec.txt"))通过上述命令可以完成了训练集,验证集和测试集的制作,制作完成的数据集信息如下:
| 类型 | 数据集 | 图片数量 |
|---|---|---|
| 检测 | 训练集 | 5769 |
| 检测 | 验证集 | 1001 |
| 检测 | 测试集 | 5006 |
| 识别 | 训练集 | 5769 |
| 识别 | 验证集 | 1001 |
| 识别 | 测试集 | 5006 |
| 由于数据集比较少,为了模型更好和更快的收敛,这里选用 PaddleOCR 中的 PP-OCRv3 模型进行文本检测和识别,并且使用 PP-OCRv3 模型参数作为预训练模型。 |
PP-OCRv3在PP-OCRv2的基础上,中文场景端到端Hmean指标相比于PP-OCRv2提升5%, 英文数字模型端到端效果提升11%。
PP-OCR 的发展过程
PP-OCR v1
其主要流程是 DB 文字检测 + 方向分类+ CRNN 字符识别
超轻量级中文OCR模型,总模型仅8.6M
单模型支持中英文数字组合识别、竖排文本识别、长文本识别
检测模型 DB(4.1M)+识别模型 CRNN(4.5M)
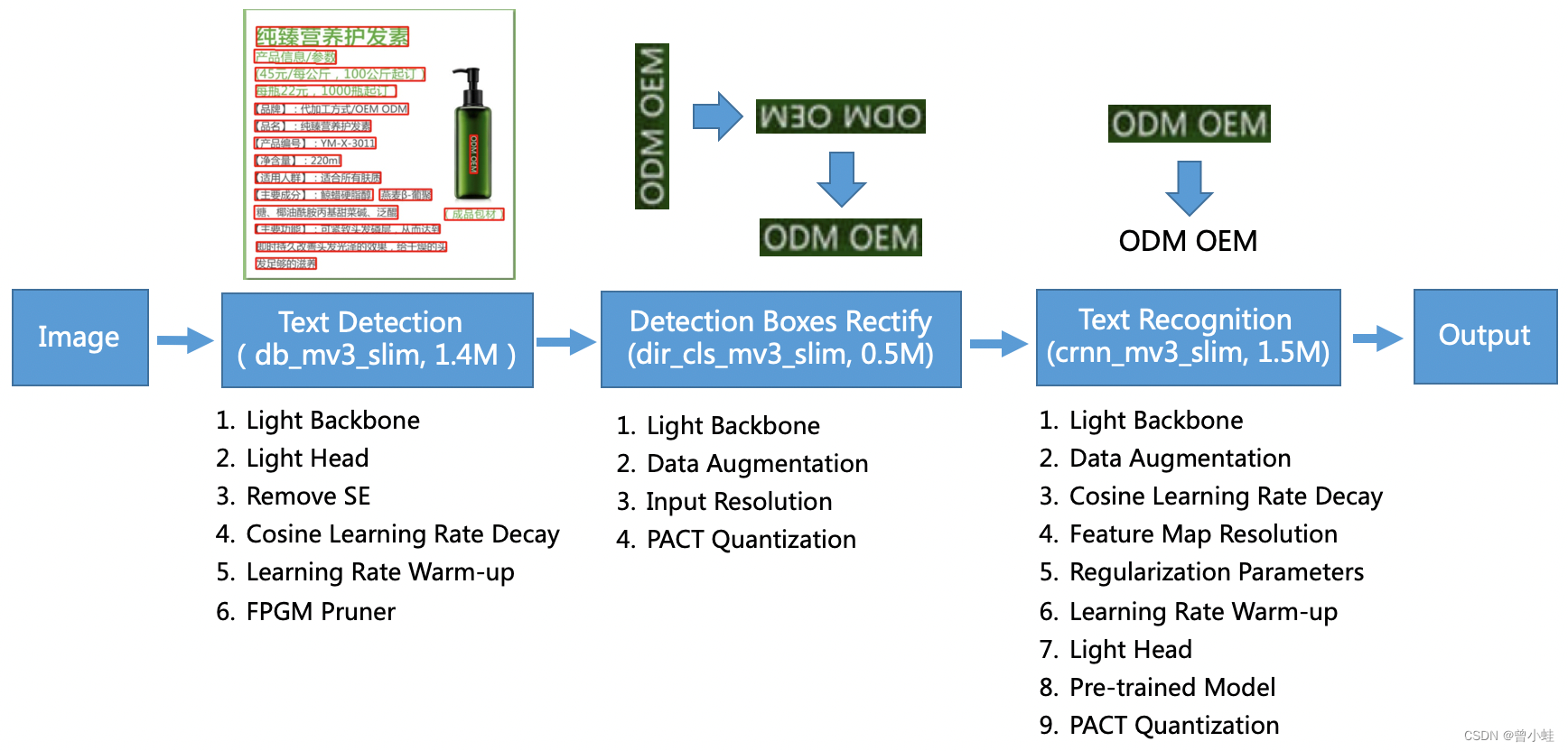
该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及 模型自动裁剪量化 8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身。
其中 DBnet 的结构不在这里赘述,会有章节单独说明。
主要是字符识别方面,v1 使用了 CRNN 进行检测。
结构图如下:
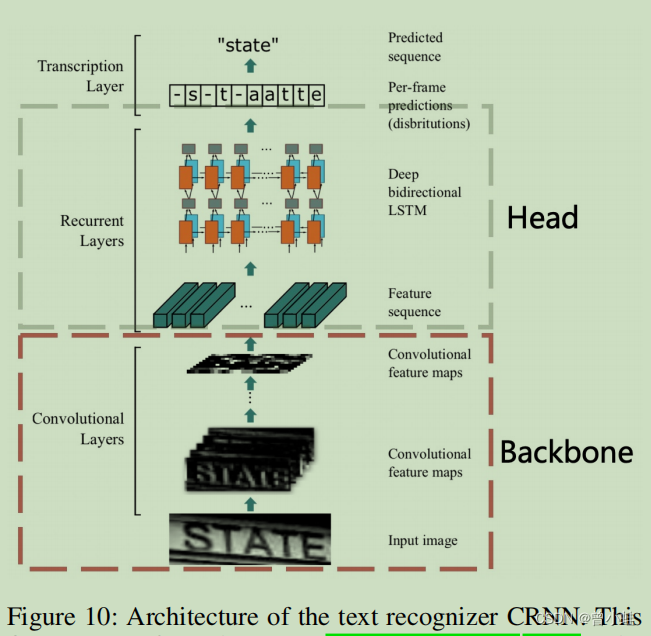
先卷积,后使用LSTM处理。
PP-OCR v2
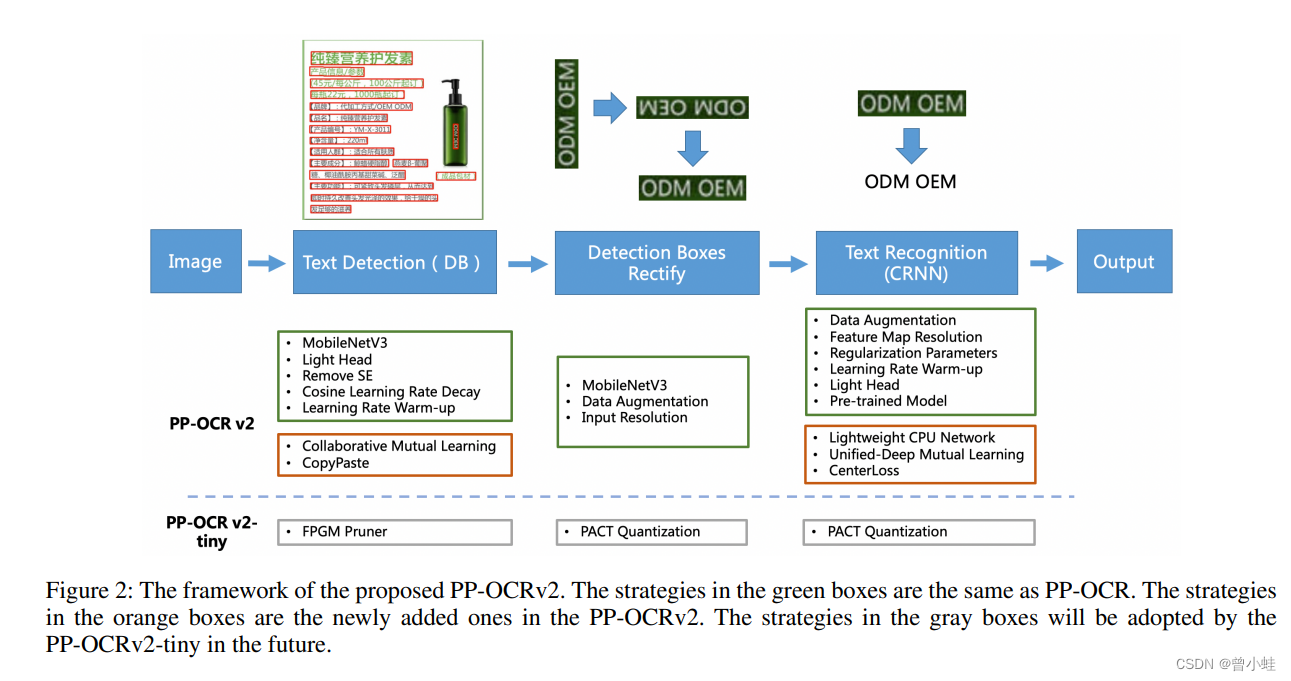
PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化:
检测模型方面:
- 采用了 CML 协同学习
- CopyPaste 数据增广策略
识别模型方面:
- 采用 LCNet 轻量级骨干网络
- UDML 改进知识蒸馏策略
- Enhanced CTC loss 损失函数改进
PP-OCR v3
中文场景,相对于PP-OCRv2中文模型提升超5%;
英文数字场景,相比于PP-OCRv2英文模型提升11%;
多语言场景,优化80+语种识别效果,平均准确率提升超5%。
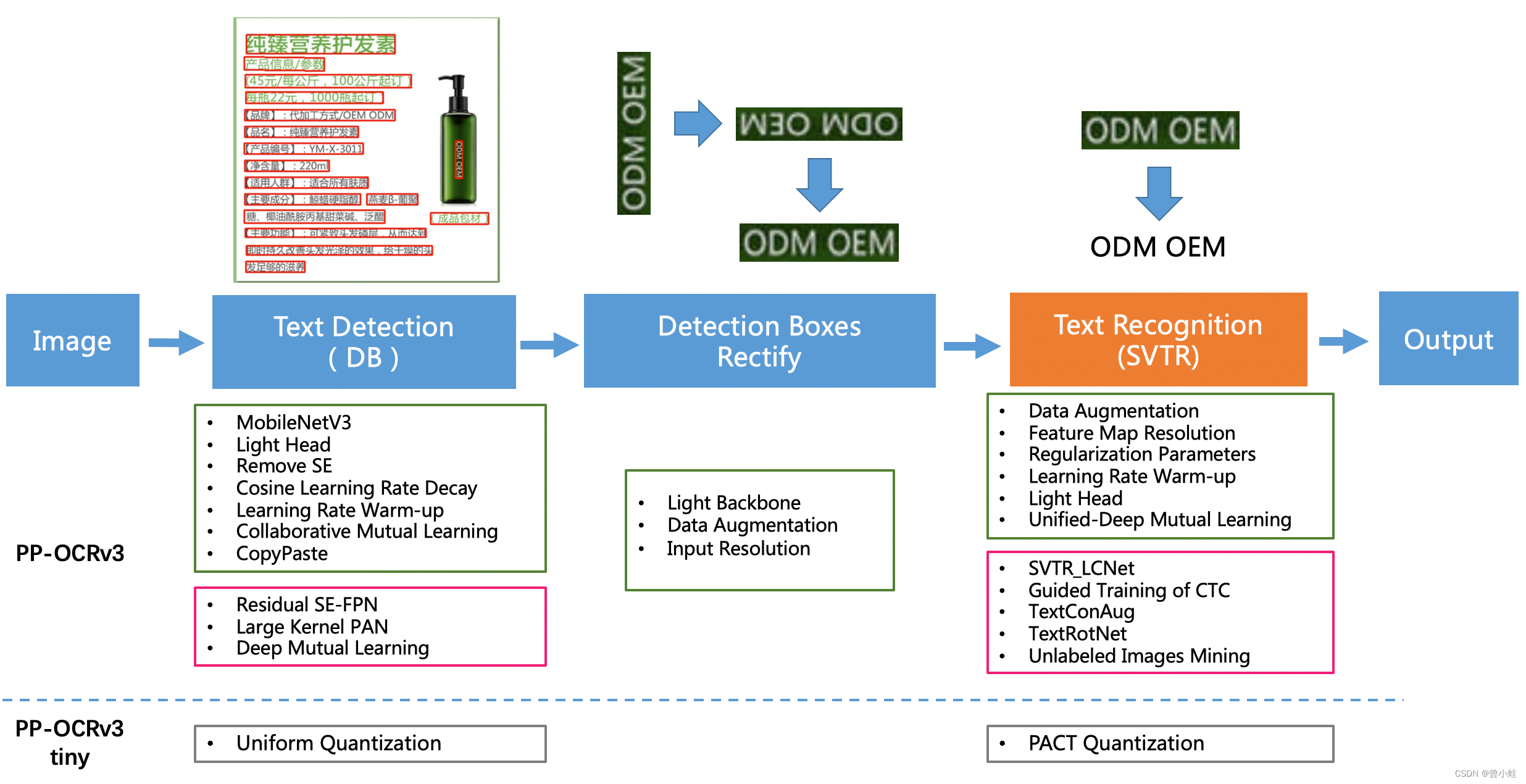
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。
SVTR不再采用RNN结构,通过引入Transformers (注意力机制)结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。
直接将PP-OCRv2的识别模型,替换成SVTR_Tiny,识别准确率从74.8%提升到80.1%(+5.3%),但是预测速度慢了将近11倍,CPU上预测一条文本行,将近100ms。
PP-OCRv3检测模型是对PP-OCRv2中的 CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了传统的Teacher指导Student的标准蒸馏与 Students 网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
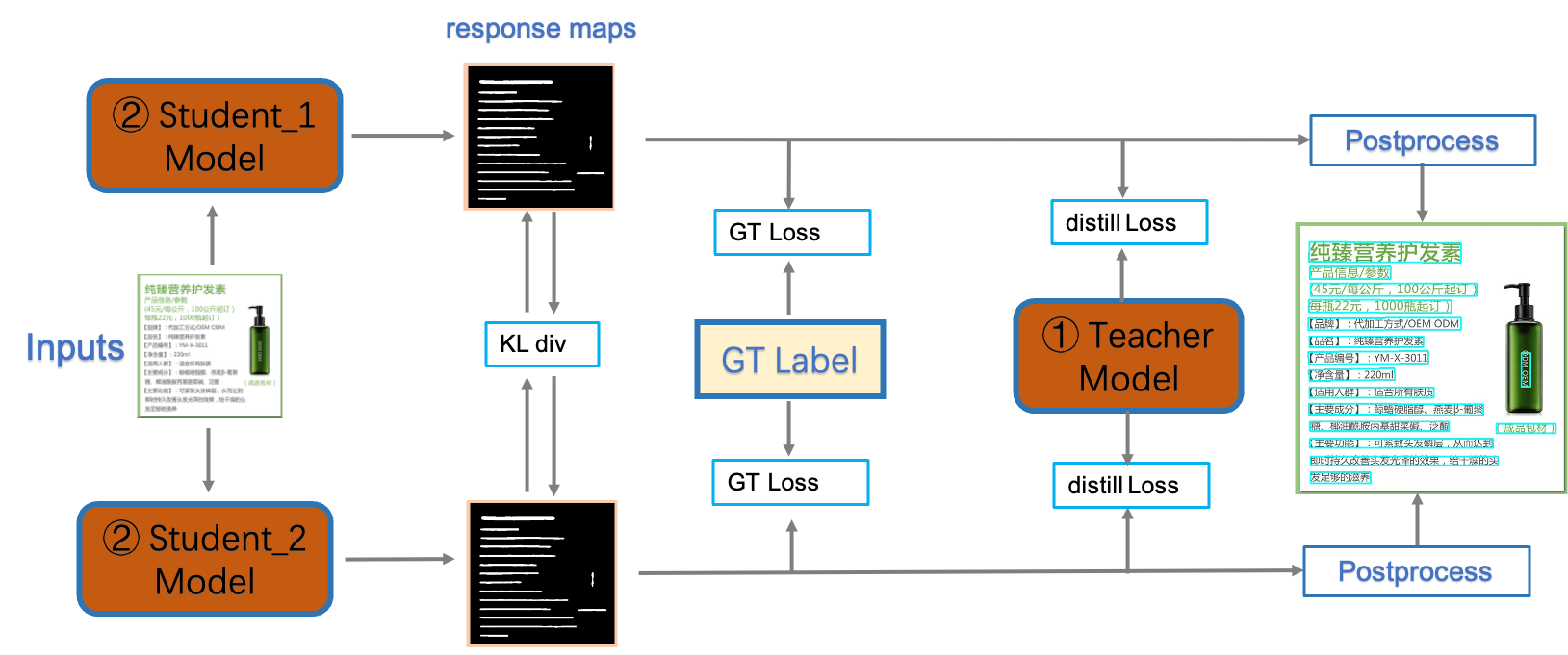
检测模块:
LK-PAN:大感受野的PAN结构;DML:教师模型互学习策略;
RSE-FPN:残差注意力机制的FPN结构;
识别模块:
SVTR_LCNet:轻量级文本识别网络;
GTC:Attention指导CTC训练策略;
TextConAug:挖掘文字上下文信息的数据增广策略;
TextRotNet:自监督的预训练模型;
UDML:联合互学习策略;
UIM:无标注数据挖掘方案。 从效果上看,速度可比情况下,多种场景精度均有大幅提升:
PP-OCR v4
从效果上看,速度可比情况下:
中文场景,相对于PP-OCRv3中文模型提升超4%;
英文数字场景,相比于PP-OCRv3英文模型提升6%;
多语言场景,优化80个语种识别效果,平均准确率提升超8%。
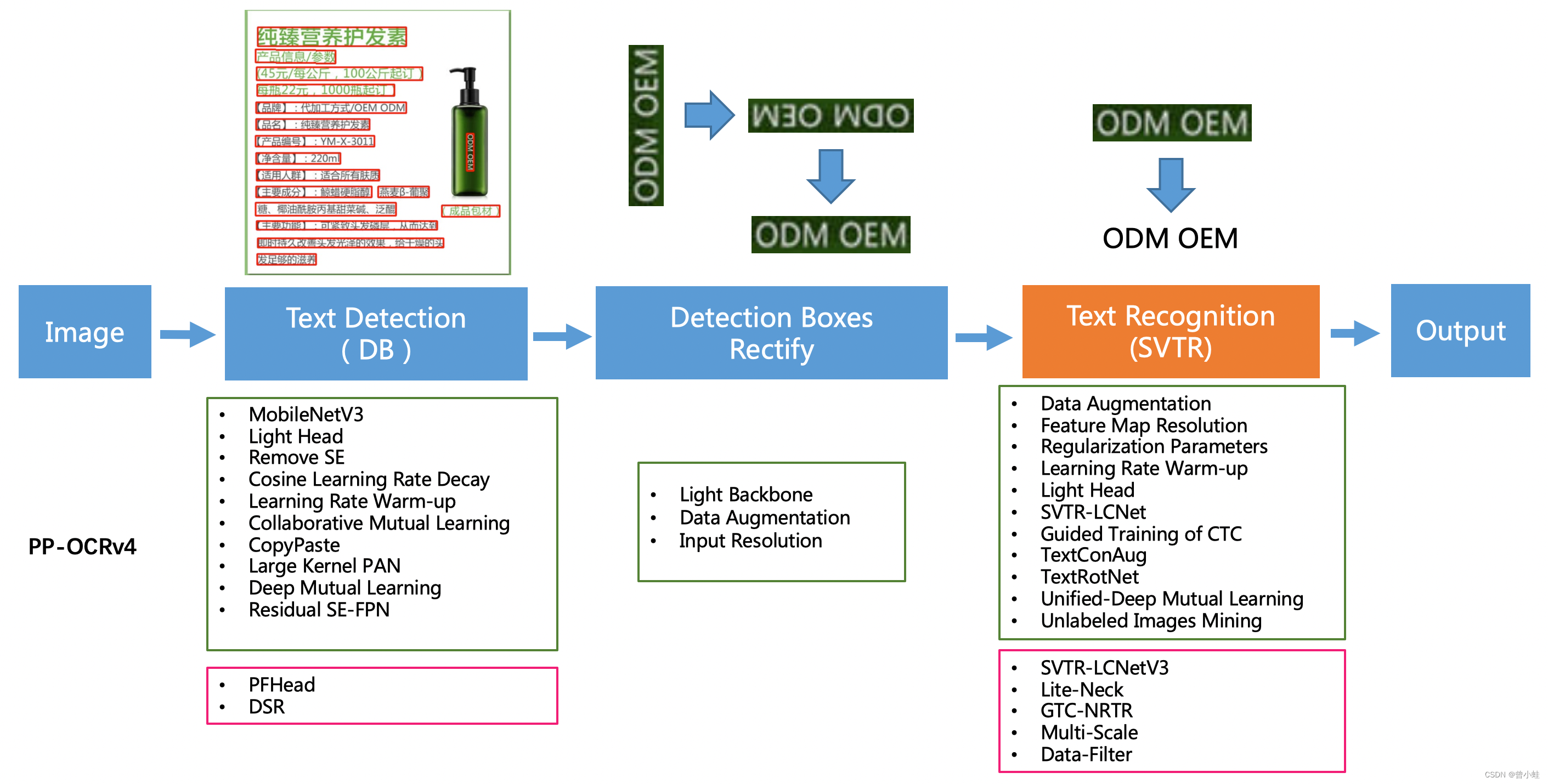
从算法改进思路上看,分别针对检测和识别模型,进行了一下改进:
检测模块:LCNetV3:精度更高的骨干网络
PFHead:并行head分支融合结构
DSR: 训练中动态增加shrink ratioCML:添加Student和Teacher网络输出的KL div loss
识别模块:SVTR_LCNetV3:精度更高的骨干网络
Lite-Neck:精简的Neck结构
GTC-NRTR:稳定的Attention指导分支
Multi-Scale:多尺度训练策略
DF: 数据挖掘方案
DKD :DKD蒸馏策略
正式开始进行实践
文字检测 👇
使用的框架是 ch_PP-OCRv3_det 框架。
下面是对 ch_PP-OCRv3_det 框架配置文件的详解:
Global:
debug: false
use_gpu: true
epoch_num: 50
log_smooth_window: 20
print_batch_step: 5
save_model_dir: ./output/ch_PP-OCR_V3_det/
save_epoch_step: 50
eval_batch_step:
- 0
- 50
cal_metric_during_train: false
pretrained_model: https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
checkpoints: null
save_inference_dir: null
use_visualdl: false
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./checkpoints/det_db/predicts_db.txt
distributed: true
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: True
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 2
regularizer:
name: L2
factor: 5.0e-05
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- IaaAugment:
augmenter_args:
- type: Fliplr
args:
p: 0.5
- type: Affine
args:
rotate:
- -10
- 10
- type: Resize
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 960
- 960
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 8
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- DetResizeForTest: null
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- shape
- polys
- ignore_tags
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2可以看到其中的骨干网络是 MobileNetv3 Neck 用的是 RSEFPN,Head 是 DBHead。
模型详解
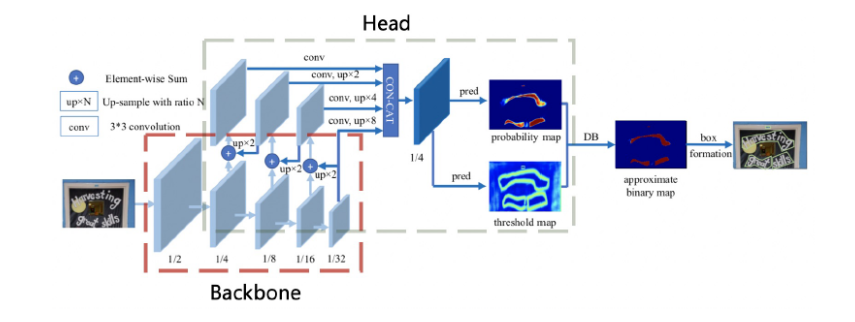
其中的 Backbone,是一个典型的 FPN,但是在 FPN 中,它使用了 deformable convolution(可变性卷积)其具有更灵活的感受野,有利于长文本检测。
DB 文本检测模型可以分为三个部分:
• Backbone 网络,负责提取图像的特征
• FPN 网络,特征金字塔结构增强特征
• Head 网络,计算文本区域概率图
DB Head 网络会在 FPN 特征的基础上作上采样,将 FPN 特征由原图的四分之一大小映射到原图大小。
DB-Head
DBNet 就是基于分割的算法。这种算法对于弯曲文本的检测会更加准确,但是会存在有一个后处理的过程,在通常的后处理过程中,它的二值化是有一个固定的阈值来实现,而这个阈值对于模型的性能影响是比较大的。
而在 DBNet 中提出了一个可微分的二值化模块,也就是 DB module。这个 DB module 可以自适应学习每个像素点的二值化阈值,所以其本质上是把二值化这个步骤加入到了网络中来训练。
好处是可以简化后处理的过程,同时还能增强模型的性能。这是 DBNet 最大的贡献。
传统的文本检测模型的处理方法是如下图中蓝色线所示:
首先的得到分割图。其中设置一个固定的阈值,再将分割图转换成二值化图,然后再使用一系列的方法得到最终的检测结果。
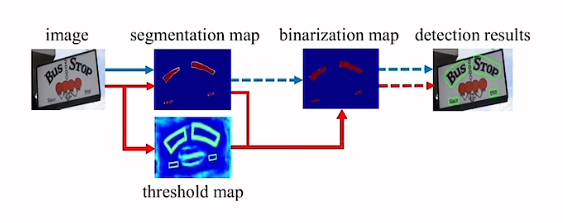
而在 DBNet 中,提出了 threshold map(阈值图)这样的一个单独的分支,这样就可以实现在每个像素点上实现自适应的阈值,但是这里遇到了一个问题,就是标准的二值化函数是不可微分的,不可微分也就是意味着不能在网络中进行联合训练。所以,在此基础上,提出了一个近似的二值化函数,叫做 Differentiable Binarization (DB)。用这个二值化函数去替代标准的二值化函数,让模型可以实现端到端的训练。
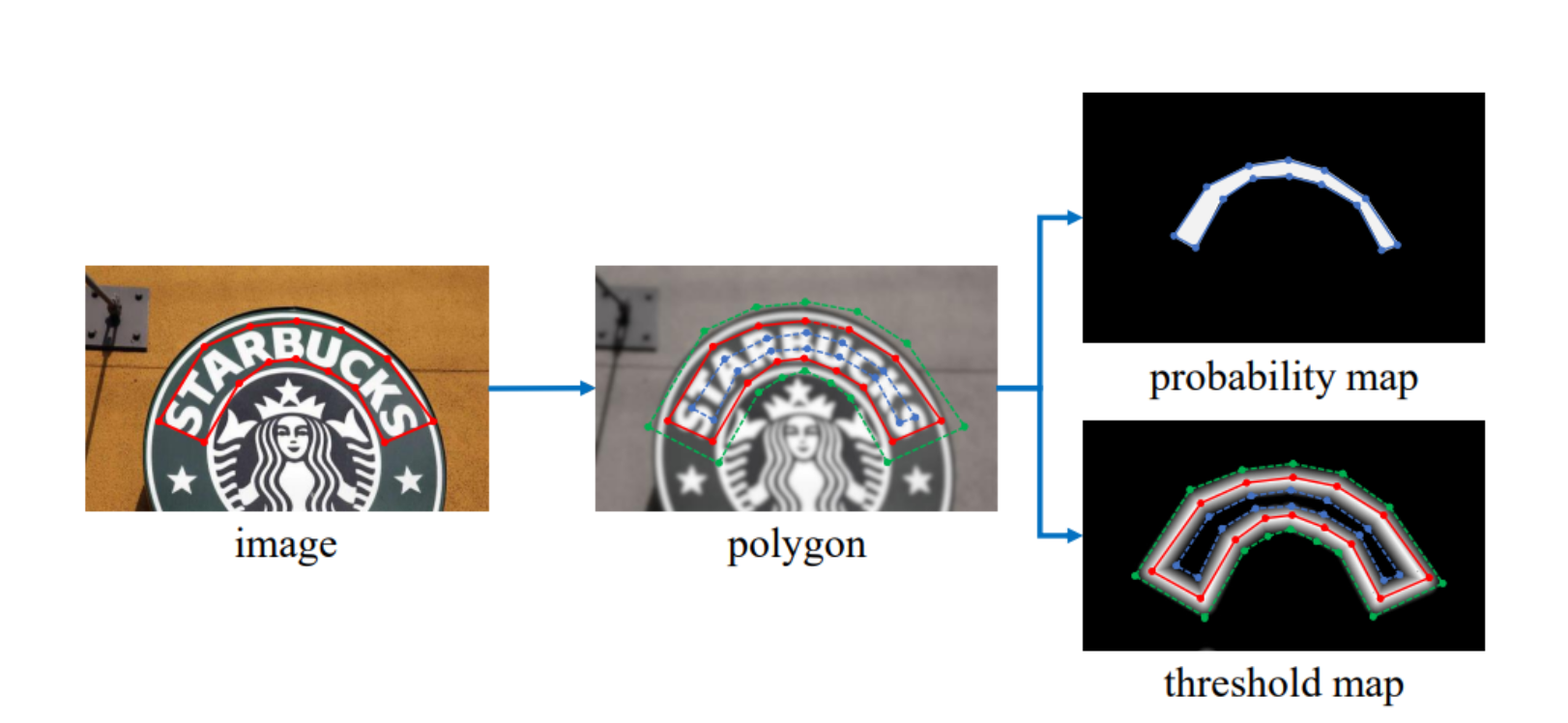
DBNet 通过骨干网络 (backbone) 提取特征,使用 DBFPN 的结构 (neck) 对各阶段的特征进行融合,得到融合后的特征。融合后的特征经过卷积等操作 (head) 进行解码,生成概率图和阈值图,二者融合后计算得到一个近似的二值图。计算损失函数时,对这三个特征图均计算损失函数,这里把二值化的监督也也加入训练过程,从而让模型学习到更准确的边界。
其最后其实是得到目标图像的二值化图,然后在进行轮廓提取、边界框生成,最后得到结果。
Backbone - MobileNet
MobileNet系列是谷歌推出的轻量级网络模型,旨在不过多牺牲模型性能的同时大幅度减小模型的尺寸和加快模型的运算速度。
MobileNet v1
MobileNet V1基于一种流线型结构使用深度可分离卷积来构造轻型权重深度神经网络。
网络结构
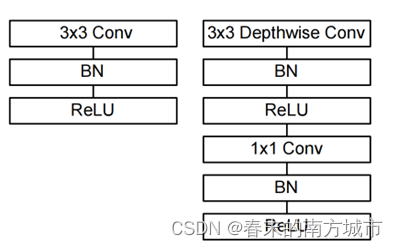
MobileNet 一共有28层,13组深度可分离卷积,除第一层为全卷积其他全由深度可分离卷积构成。所有的层都跟着一个BN以及ReLU非线性激活函数,除了最后一层全连接层没有非线性激活函数,是直接送入softmax 层进行分类。
模型中主要包含两个权衡延迟和准确率的全局超参数-宽度乘法器 (width multiplier) 和分辨率乘法器(resolution multiplier),允许模型构造器能够根据特定问题选择合适大小的模型。
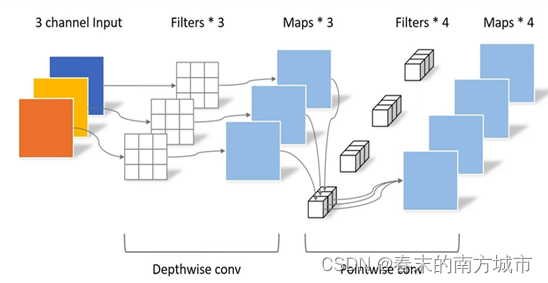
深度可分离卷积是一种将标准卷积分解成深度卷积以及一个1x1的卷积即逐点卷积。能够有效减少计算量以及模型的大小。
如下图中所示:
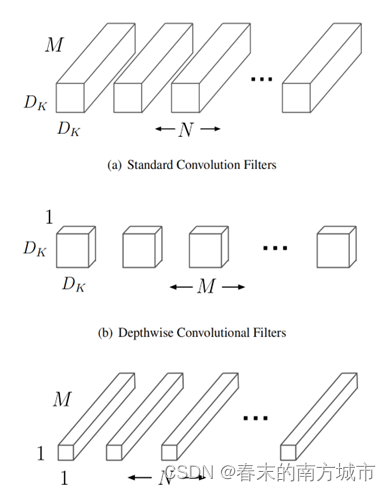
一个 3x3 Conv 被拆分成了 3x3 Depthwise Conv和 1x1 Conv
这样一来,计算量就大大减少了。
MobileNet一共有28层,13组深度可分离卷积,除第一层为全卷积其他全由深度可分离卷积构成。所有的层都跟着一个BN以及ReLU非线性激活函数,除了最后一层全连接层没有非线性激活函数直接送入 softmax 层进入分类。
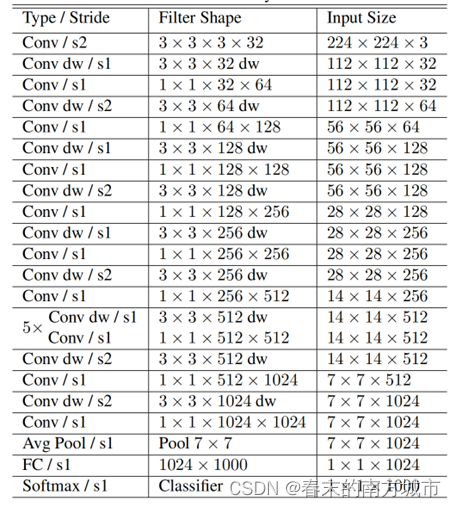
网络结构模块:
MobileNet v2
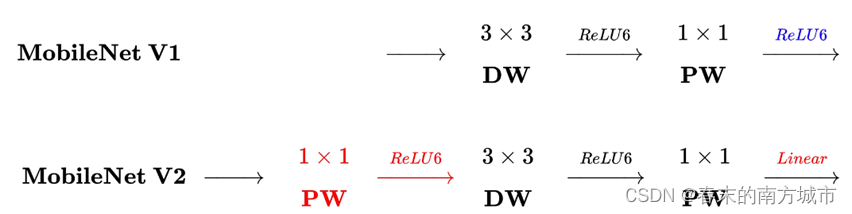
MobileNetV2网络设计基于MobileNet V1,它保留了其简单性且不需任何特殊的运算符,同时显着提高了其准确性,从而实现了针对移动应用程序的图像分类和检测任务等。网络中的亮点是 Inverted Residuals (倒残差结构 )和 Linear Bottlenecks(线性瓶颈)。
模型主要贡献是提出了具有线性瓶颈的倒置残差块-Bottleneck Residual Block。该模块将低维压缩表示作为输入,首先将其扩展到高维,然后使用的深度可分离卷积进行提取特征。随后将特征投影回具有线性卷积的低维表示。
具有线性瓶颈的倒置残差块-Bottleneck Residual Block:
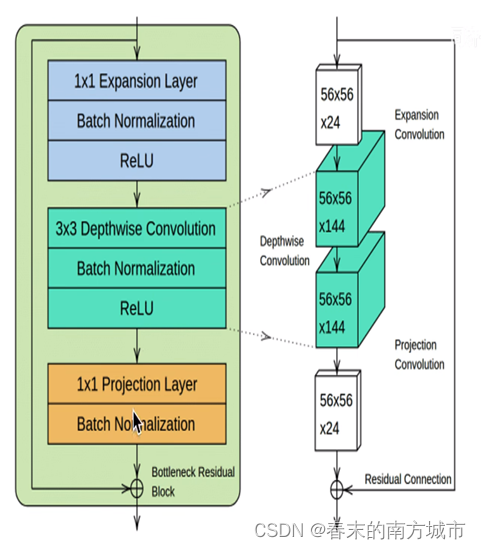
a.扩展卷积-Expansion Convolution
使用1x1大小卷积核增加输入特征图的通道数(升维)。让Depthwise Convolution有更多机会获取有效信息。
b.深度可分离卷积-Depthwise Convolution
和MobileNetV1一致。
c.投影卷积-Projection Convolution
Projection Convolution是大小为1x1的卷积核(降维),输出通道数远小于输入通道数,从而达到限制模型大小的目的。
d.残差连接-Residual Connection
借鉴了ResNet的理念,插入"short-cut"的目的是为了帮助梯度在不同网络层间的传播。使用Residual connection要满足条件:输入特征图尺寸等于输出特征图尺寸。
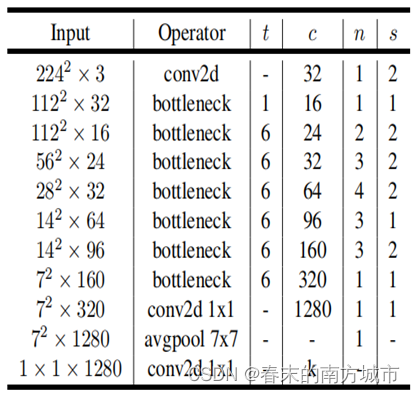
网络结构
基本构建块是一个具有残差的瓶颈深度可分离卷积。包含具有32个通道的初始全卷积层,然后是下表中所述的19个残差瓶颈层。将ReLU6用作非线性函数,因为它与低精度计算一起使用时具有鲁棒性。始终使用3×3的内核大小,并在训练过程中利用dropout和BN.
MnasNet
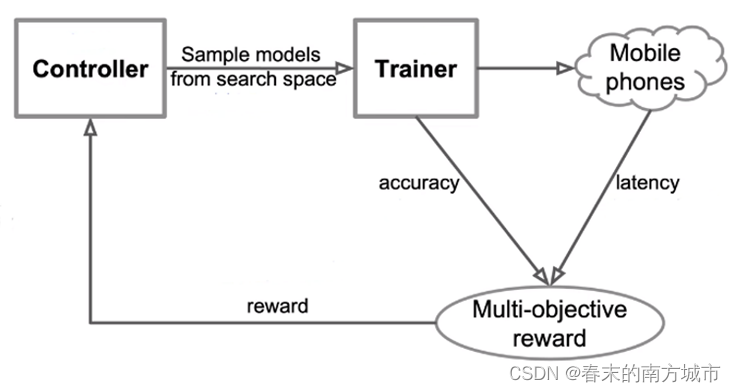
MnasNet介于V2和V3之间,主要有两个亮点:
多目标优化函数:准确度性能+真实手机推理时间
分层的神经架构搜索空间。
其主要是使用多目标优化的目标函数,兼顾速度和精度,其中速度用真实手机推断时间衡量提出分层的神经网络架构搜索空间,将卷积神经网络分解为若干block,分别搜索各自基本模块,保证层结构多样性。
网络结构
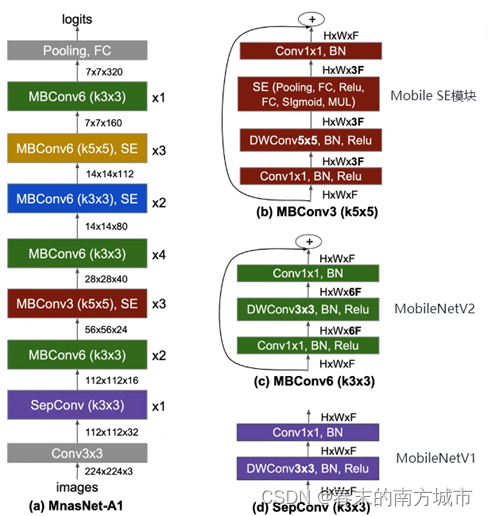
MobileNet v3
MobileNetV3综合了三种模型的思想:MobileNetV1的深度可分离卷积(depthwise separable convolutions)、MobileNetV2的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck)和MnasNet的基于squeeze and excitation结构的轻量级注意力模型。
1.互补搜索技术
•资源受限的NAS:计算和参数量受限前提下搜索网络的各个模块
•NetAdapt:用于对NAS搜索的各个模块网络层的微调。
2.适用于移动环境的新的高效非线性版本:
•重新设计的激活函数hard-swish()
3.新的高效网络设计:
•降低卷积核数量并用不同的激活方式降低冗余
•精简Last Stage
4.新的高效分割解码器:
•MobileNetV3-Large
•MobileNetV3-Small
在更新 Block 的过程中,加入了 SE 模块。
在V3中使用(squeeze-and-excite,SE) 模块,将 expansion layer的channel变为原来的1/4,即提高了精度,也没有增加时间消耗。并且SE结构放在了depthwise 之后。实质为引入了一个 channel 注意力机制。
Backbone 相关代码
Backbone 相关代码在 ppocr/modeling/backbone/det_mobilenet_v3.py 中。
class MobileNetV3(nn.Layer):
def __init__(
self, in_channels=3, model_name="large", scale=0.5, disable_se=False, **kwargs
):
"""
the MobilenetV3 backbone network for detection module.
Args:
params(dict): the super parameters for build network
"""
super(MobileNetV3, self).__init__()
self.disable_se = disable_se
if model_name == "large":
cfg = [
# k, exp, c, se, nl, s,
# 卷积核大小、扩展通道数、输出通道数、是否使用 SE 模块、激活函数、步长
[3, 16, 16, False, "relu", 1],
[3, 64, 24, False, "relu", 2],
[3, 72, 24, False, "relu", 1],
[5, 72, 40, True, "relu", 2],
[5, 120, 40, True, "relu", 1],
[5, 120, 40, True, "relu", 1],
[3, 240, 80, False, "hardswish", 2],
[3, 200, 80, False, "hardswish", 1],
[3, 184, 80, False, "hardswish", 1],
[3, 184, 80, False, "hardswish", 1],
[3, 480, 112, True, "hardswish", 1],
[3, 672, 112, True, "hardswish", 1],
[5, 672, 160, True, "hardswish", 2],
[5, 960, 160, True, "hardswish", 1],
[5, 960, 160, True, "hardswish", 1],
]
cls_ch_squeeze = 960
elif model_name == "small":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, True, "relu", 2],
[3, 72, 24, False, "relu", 2],
[3, 88, 24, False, "relu", 1],
[5, 96, 40, True, "hardswish", 2],
[5, 240, 40, True, "hardswish", 1],
[5, 240, 40, True, "hardswish", 1],
[5, 120, 48, True, "hardswish", 1],
[5, 144, 48, True, "hardswish", 1],
[5, 288, 96, True, "hardswish", 2],
[5, 576, 96, True, "hardswish", 1],
[5, 576, 96, True, "hardswish", 1],
]
cls_ch_squeeze = 576
else:
raise NotImplementedError(
"mode[" + model_name + "_model] is not implemented!"
)
supported_scale = [0.35, 0.5, 0.75, 1.0, 1.25]
assert (
scale in supported_scale
), "supported scale are {} but input scale is {}".format(supported_scale, scale)
inplanes = 16
# conv1
self.conv = ConvBNLayer(
in_channels=in_channels,
out_channels=make_divisible(inplanes * scale),
kernel_size=3,
stride=2,
padding=1,
groups=1,
if_act=True,
act="hardswish",
)
self.stages = []
self.out_channels = []
block_list = []
i = 0
inplanes = make_divisible(inplanes * scale)
for k, exp, c, se, nl, s in cfg:
se = se and not self.disable_se
start_idx = 2 if model_name == "large" else 0
if s == 2 and i > start_idx:
self.out_channels.append(inplanes)
self.stages.append(nn.Sequential(*block_list))
block_list = []
block_list.append(
ResidualUnit(
in_channels=inplanes,
mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c),
kernel_size=k,
stride=s,
use_se=se,
act=nl,
)
)
inplanes = make_divisible(scale * c)
i += 1
block_list.append(
ConvBNLayer(
in_channels=inplanes,
out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1,
stride=1,
padding=0,
groups=1,
if_act=True,
act="hardswish",
)
)
self.stages.append(nn.Sequential(*block_list))
self.out_channels.append(make_divisible(scale * cls_ch_squeeze))
for i, stage in enumerate(self.stages):
self.add_sublayer(sublayer=stage, name="stage{}".format(i))
def forward(self, x):
x = self.conv(x)
out_list = []
for stage in self.stages:
x = stage(x)
out_list.append(x)
return out_list
class ConvBNLayer(nn.Layer):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=1,
if_act=True,
act=None,
):
super(ConvBNLayer, self).__init__()
self.if_act = if_act
self.act = act
self.conv = nn.Conv2D(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias_attr=False,
)
self.bn = nn.BatchNorm(num_channels=out_channels, act=None)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.if_act:
if self.act == "relu":
x = F.relu(x)
elif self.act == "hardswish":
x = F.hardswish(x)
else:
print(
"The activation function({}) is selected incorrectly.".format(
self.act
)
)
exit()
return x在调试中查看Mobile Net
这里其实需要注意,由于是用的框架,所以其实本质上是 backbone 上使用了 MobileNet v3 的backbone。
MobileNetV3(
(conv): ConvBNLayer(
(conv): Conv2D(3, 8, kernel_size=[3, 3], stride=[2, 2], padding=1, data_format=NCHW)
(bn): BatchNorm()
)
(stage0): Sequential(
(0): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(8, 8, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(8, 8, kernel_size=[3, 3], padding=1, groups=8, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(8, 8, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(1): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(8, 32, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(32, 32, kernel_size=[3, 3], stride=[2, 2], padding=1, groups=32, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(32, 16, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(2): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(16, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(40, 40, kernel_size=[3, 3], padding=1, groups=40, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(40, 16, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
)
(stage1): Sequential(
(0): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(16, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(40, 40, kernel_size=[5, 5], stride=[2, 2], padding=2, groups=40, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(40, 24, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(1): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(24, 64, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(64, 64, kernel_size=[5, 5], padding=2, groups=64, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(64, 24, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(2): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(24, 64, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(64, 64, kernel_size=[5, 5], padding=2, groups=64, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(64, 24, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
)
(stage2): Sequential(
(0): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(24, 120, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(120, 120, kernel_size=[3, 3], stride=[2, 2], padding=1, groups=120, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(120, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(1): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(40, 104, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(104, 104, kernel_size=[3, 3], padding=1, groups=104, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(104, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(2): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(40, 96, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(96, 96, kernel_size=[3, 3], padding=1, groups=96, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(96, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(3): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(40, 96, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(96, 96, kernel_size=[3, 3], padding=1, groups=96, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(96, 40, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(4): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(40, 240, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(240, 240, kernel_size=[3, 3], padding=1, groups=240, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(240, 56, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(5): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(56, 336, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(336, 336, kernel_size=[3, 3], padding=1, groups=336, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(336, 56, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
)
(stage3): Sequential(
(0): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(56, 336, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(336, 336, kernel_size=[5, 5], stride=[2, 2], padding=2, groups=336, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(336, 80, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(1): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(80, 480, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(480, 480, kernel_size=[5, 5], padding=2, groups=480, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(480, 80, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(2): ResidualUnit(
(expand_conv): ConvBNLayer(
(conv): Conv2D(80, 480, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
(bottleneck_conv): ConvBNLayer(
(conv): Conv2D(480, 480, kernel_size=[5, 5], padding=2, groups=480, data_format=NCHW)
(bn): BatchNorm()
)
(linear_conv): ConvBNLayer(
(conv): Conv2D(480, 80, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
(3): ConvBNLayer(
(conv): Conv2D(80, 480, kernel_size=[1, 1], data_format=NCHW)
(bn): BatchNorm()
)
)
)Backbone 网络结构
通过,观察变量中的含义:
上来首先是一个 ConvBNLayer,是要构建一个卷积、批归一化块 ConvBNLayer ,包含卷积层和BatchNorm层。
其实就是将卷积和批归一化以及激活函数封装为 ConvBNLayer.
BatchNorm (): 批归一化层。
BN就是通过归一化手段,将每层输入强行拉回均值0方差为1的标准正态分布,这样使得激活输入值分布在非线性函数梯度敏感区域,从而避免梯度消失问题,大大加快训练速度。
第一个卷归层通过一个卷积核为 3、步长为 2 的卷归层,将输入张量的通道数由 3 转为 8 通道输出,宽高各压缩一半。
然后是 Stage 0 部分:
包含 3 个 ResidualUnit,每个单元包含 3 个 ConvBNLayer。
其中 expand_conv: 扩展卷积层。 Bottleneck_conv: 瓶颈卷积层,使用分组卷积。 Linear_conv: 线性卷积层。
通过三个残差层,将输入通道 8 转为 16 通道输出,宽高各压缩一半。
Stage 1 部分: 包含 3 个 ResidualUnit,每个单元包含 3 个 ConvBNLayer,与 stage 0 类似,但通道数和卷积核大小不同。 (PS:ResidualUnit 是残差学习单元)这一部分通常是网络的初始阶段,负责对输入图像进行初步的特征提取。包含较少的卷积层和残差单元。通过三个残差层,将输入通道 8 转为 16 通道输出,宽高各压缩一半。
Stage 2 部分: 包含 6 个 ResidualUnit,每个单元包含 3 个 ConvBNLayer,与 stage 0 和 stage 1 类似,但通道数和卷积核大小不同。这一部分是中间阶段,进一步提取更高层次的特征。包含更多的卷积层和残差单元。通过六个残差层,将输入通道 24 转为 56 通道输出,宽高各压缩一半。
Stage 3 部分: 包含 4 个 ResidualUnit 和 1 个 ConvBNLayer,每个单元包含 3 个 ConvBNLayer,与前面的 stage 类似,但通道数和卷积核大小不同。这一部分是更深层次的阶段,提取更复杂的特征。包含更多的卷积层和残差单元。通过三个残差层和一个卷归层,将输入通道 56 转为 480 通道输出,宽高各压缩一半。


个人觉得这里设计成每次处理之后都压缩一半的目的是为了配合 Neck 部分做特征金字塔(FeaturePyramidNetwork)
Neck - RSEFPN
可以注意到,配置文件中使用的相关配置如下:
Neck:
name: RSEFPN
out_channels: 96
shortcut: True可以看出颈部网络的名称为RSEFPN,这个名字可以拆开来做如下理解:
RSE-FPN:残差注意力机制的FPN结构;
- R
代表残差(Residual),即输入特征与中间输出特征做加法,形成最终输出特征。 - SE
代表压发层(Squeeze&Excitation),即通道注意力机制,通过压制与发扬,减弱低效通道作用,强化高效通道效能。 - FPN
代表特征金字塔(FeaturePyramidNetwork),即在各个不同尺度上提取目标特征,形成一个原始图像从整体到细节的全方位理解。参照上节的分析,骨干网通过四个阶段,分别在1/4、1/8、1/16、1/32等四个层次上进行操作。
RSE-FPN 相关代码
class RSEFPN(nn.Layer):
def __init__(self, in_channels, out_channels, shortcut=True, **kwargs):
super(RSEFPN, self).__init__()
self.out_channels = out_channels
self.ins_conv = nn.LayerList()
self.inp_conv = nn.LayerList()
self.intracl = False
if "intracl" in kwargs.keys() and kwargs["intracl"] is True:
self.intracl = kwargs["intracl"]
self.incl1 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
self.incl2 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
self.incl3 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
self.incl4 = IntraCLBlock(self.out_channels // 4, reduce_factor=2)
for i in range(len(in_channels)):
self.ins_conv.append(
RSELayer(in_channels[i], out_channels, kernel_size=1, shortcut=shortcut)
)
self.inp_conv.append(
RSELayer(
out_channels, out_channels // 4, kernel_size=3, shortcut=shortcut
)
)
def forward(self, x):
c2, c3, c4, c5 = x
in5 = self.ins_conv[3](c5)
in4 = self.ins_conv[2](c4)
in3 = self.ins_conv[1](c3)
in2 = self.ins_conv[0](c2)
out4 = in4 + F.upsample(
in5, scale_factor=2, mode="nearest", align_mode=1
) # 1/16
out3 = in3 + F.upsample(
out4, scale_factor=2, mode="nearest", align_mode=1
) # 1/8
out2 = in2 + F.upsample(
out3, scale_factor=2, mode="nearest", align_mode=1
) # 1/4
p5 = self.inp_conv[3](in5)
p4 = self.inp_conv[2](out4)
p3 = self.inp_conv[1](out3)
p2 = self.inp_conv[0](out2)
if self.intracl is True:
p5 = self.incl4(p5)
p4 = self.incl3(p4)
p3 = self.incl2(p3)
p2 = self.incl1(p2)
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse通过代码,可以认为结构如下图:
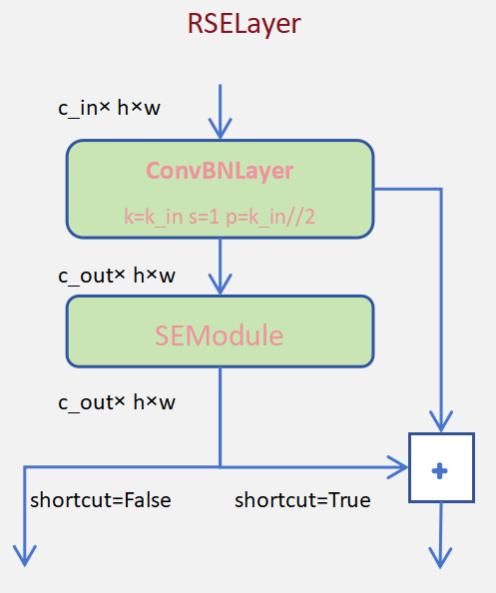
从上到下看残注层结构示意图,首先是传入了一个输入通道数c_in的张量,结构为c_in,h,w,经过一个卷积核为k_in步长为1的卷归层的处理,输出一个结构为c_out,h,w的张量,其中c_out代表设置的输出通道数。接着是一个压发层SEModule,不改变输入张量结构。最后根据short_cut参数是否为True,来决定是否将压发层的结果与压发层的输入做加法。
在调试中查看 Neck
RSEFPN(
(ins_conv): LayerList(
(0): RSELayer(
(in_conv): Conv2D(16, 96, kernel_size=[1, 1], data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(96, 24, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(24, 96, kernel_size=[1, 1], data_format=NCHW)
)
)
(1): RSELayer(
(in_conv): Conv2D(24, 96, kernel_size=[1, 1], data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(96, 24, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(24, 96, kernel_size=[1, 1], data_format=NCHW)
)
)
(2): RSELayer(
(in_conv): Conv2D(56, 96, kernel_size=[1, 1], data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(96, 24, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(24, 96, kernel_size=[1, 1], data_format=NCHW)
)
)
(3): RSELayer(
(in_conv): Conv2D(480, 96, kernel_size=[1, 1], data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(96, 24, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(24, 96, kernel_size=[1, 1], data_format=NCHW)
)
)
)
(inp_conv): LayerList(
(0): RSELayer(
(in_conv): Conv2D(96, 24, kernel_size=[3, 3], padding=1, data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(24, 6, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(6, 24, kernel_size=[1, 1], data_format=NCHW)
)
)
(1): RSELayer(
(in_conv): Conv2D(96, 24, kernel_size=[3, 3], padding=1, data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(24, 6, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(6, 24, kernel_size=[1, 1], data_format=NCHW)
)
)
(2): RSELayer(
(in_conv): Conv2D(96, 24, kernel_size=[3, 3], padding=1, data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(24, 6, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(6, 24, kernel_size=[1, 1], data_format=NCHW)
)
)
(3): RSELayer(
(in_conv): Conv2D(96, 24, kernel_size=[3, 3], padding=1, data_format=NCHW)
(se_block): SEModule(
(avg_pool): AdaptiveAvgPool2D(output_size=1)
(conv1): Conv2D(24, 6, kernel_size=[1, 1], data_format=NCHW)
(conv2): Conv2D(6, 24, kernel_size=[1, 1], data_format=NCHW)
)
)
)
)通过结合代码和查看neck 结构,可以形成如下颈部网络示意图:


通过上图,可以将颈部网络划分为如下几个部分:
- 对接
需要从骨干网四个阶段输出,依此承接,参照上图左侧虚线部分,详情见上节都骨干网的分析。 - 通道统一
通过四个残注层RSELayer,将骨干网四阶段输出,统一转为96通道,宽高不变,依此形成in5/in4/in3/in2四层输出。 - 上采样
通过三个scale为2的上采样操作,将细粒度下层特征放大,并与上层结果做加法,实现各层次视觉信息的融合,依此形成out4/out3/out2 - 通道压缩
通过四个卷积核大小为3的残注层RSELayer,将上采样结果进行通道压缩,将原通道数缩为1/4,依此形成p5/p4/p3/p2 - 聚合
将通道压缩结果,依此做scale=8/4/2的上采样,将所有四层金字塔视觉信息处理成果统一转为通道数、宽、高一致的信息,在通道维度上做拼接,最终将骨干网16/24/56/480通道的四阶段输出,结果颈部网络RSEFPN的处理,形成96通道的输出,宽高与骨干网stage0的输出一致。
验证初始 student 模型
PS E:\LEARN\Project-all\AI\PaddleOCR-main> & E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe e:/LEARN/Project-all/AI/PaddleOCR-main/tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt]
[2024/12/09 16:00:51] ppocr INFO: Architecture :
[2024/12/09 16:00:51] ppocr INFO: Backbone :
[2024/12/09 16:00:51] ppocr INFO: disable_se : True
[2024/12/09 16:00:51] ppocr INFO: model_name : large
[2024/12/09 16:00:51] ppocr INFO: name : MobileNetV3
[2024/12/09 16:00:51] ppocr INFO: scale : 0.5
[2024/12/09 16:00:51] ppocr INFO: Head :
[2024/12/09 16:00:51] ppocr INFO: k : 50
[2024/12/09 16:00:51] ppocr INFO: name : DBHead
[2024/12/09 16:00:51] ppocr INFO: Neck :
[2024/12/09 16:00:51] ppocr INFO: name : RSEFPN
[2024/12/09 16:00:51] ppocr INFO: out_channels : 96
[2024/12/09 16:00:51] ppocr INFO: shortcut : True
[2024/12/09 16:00:51] ppocr INFO: Transform : None
[2024/12/09 16:00:51] ppocr INFO: algorithm : DB
[2024/12/09 16:00:51] ppocr INFO: model_type : det
[2024/12/09 16:00:51] ppocr INFO: Eval :
[2024/12/09 16:00:51] ppocr INFO: dataset :
[2024/12/09 16:00:51] ppocr INFO: data_dir : E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green
[2024/12/09 16:00:51] ppocr INFO: label_file_list : ['E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt']
[2024/12/09 16:00:51] ppocr INFO: name : SimpleDataSet
[2024/12/09 16:00:51] ppocr INFO: transforms :
[2024/12/09 16:00:51] ppocr INFO: DecodeImage :
[2024/12/09 16:00:51] ppocr INFO: channel_first : False
[2024/12/09 16:00:51] ppocr INFO: img_mode : BGR
[2024/12/09 16:00:51] ppocr INFO: DetLabelEncode : None
[2024/12/09 16:00:51] ppocr INFO: DetResizeForTest : None
[2024/12/09 16:00:51] ppocr INFO: NormalizeImage :
[2024/12/09 16:00:51] ppocr INFO: mean : [0.485, 0.456, 0.406]
[2024/12/09 16:00:51] ppocr INFO: order : hwc
[2024/12/09 16:00:51] ppocr INFO: scale : 1./255.
[2024/12/09 16:00:51] ppocr INFO: std : [0.229, 0.224, 0.225]
[2024/12/09 16:00:51] ppocr INFO: ToCHWImage : None
[2024/12/09 16:00:51] ppocr INFO: KeepKeys :
[2024/12/09 16:00:51] ppocr INFO: keep_keys : ['image', 'shape', 'polys', 'ignore_tags']
[2024/12/09 16:00:51] ppocr INFO: loader :
[2024/12/09 16:00:51] ppocr INFO: batch_size_per_card : 1
[2024/12/09 16:00:51] ppocr INFO: drop_last : False
[2024/12/09 16:00:51] ppocr INFO: num_workers : 2
[2024/12/09 16:00:51] ppocr INFO: shuffle : False
[2024/12/09 16:00:51] ppocr INFO: Global :
[2024/12/09 16:00:51] ppocr INFO: cal_metric_during_train : False
[2024/12/09 16:00:51] ppocr INFO: checkpoints : None
[2024/12/09 16:00:51] ppocr INFO: debug : False
[2024/12/09 16:00:51] ppocr INFO: distributed : False
[2024/12/09 16:00:51] ppocr INFO: epoch_num : 500
[2024/12/09 16:00:51] ppocr INFO: eval_batch_step : [0, 400]
[2024/12/09 16:00:51] ppocr INFO: infer_img : doc/imgs_en/img_10.jpg
[2024/12/09 16:00:51] ppocr INFO: log_smooth_window : 20
[2024/12/09 16:00:51] ppocr INFO: pretrained_model : models/ch_PP-OCRv3_det_distill_train/student.pdparams[2024/12/09 16:00:51] ppocr INFO: print_batch_step : 10
[2024/12/09 16:00:51] ppocr INFO: save_epoch_step : 100
[2024/12/09 16:00:51] ppocr INFO: save_inference_dir : None
[2024/12/09 16:00:51] ppocr INFO: save_model_dir : ./output/ch_PP-OCR_V3_det/
[2024/12/09 16:00:51] ppocr INFO: save_res_path : ./checkpoints/det_db/predicts_db.txt
[2024/12/09 16:00:51] ppocr INFO: use_gpu : True
[2024/12/09 16:00:51] ppocr INFO: use_visualdl : False
[2024/12/09 16:00:51] ppocr INFO: Loss :
[2024/12/09 16:00:51] ppocr INFO: alpha : 5
[2024/12/09 16:00:51] ppocr INFO: balance_loss : True
[2024/12/09 16:00:51] ppocr INFO: beta : 10
[2024/12/09 16:00:51] ppocr INFO: main_loss_type : DiceLoss
[2024/12/09 16:00:51] ppocr INFO: name : DBLoss
[2024/12/09 16:00:51] ppocr INFO: ohem_ratio : 3
[2024/12/09 16:00:51] ppocr INFO: Metric :
[2024/12/09 16:00:51] ppocr INFO: main_indicator : hmean
[2024/12/09 16:00:51] ppocr INFO: name : DetMetric
[2024/12/09 16:00:51] ppocr INFO: Optimizer :
[2024/12/09 16:00:51] ppocr INFO: beta1 : 0.9
[2024/12/09 16:00:51] ppocr INFO: beta2 : 0.999
[2024/12/09 16:00:51] ppocr INFO: lr :
[2024/12/09 16:00:51] ppocr INFO: learning_rate : 0.001
[2024/12/09 16:00:51] ppocr INFO: name : Cosine
[2024/12/09 16:00:51] ppocr INFO: warmup_epoch : 2
[2024/12/09 16:00:51] ppocr INFO: name : Adam
[2024/12/09 16:00:51] ppocr INFO: regularizer :
[2024/12/09 16:00:51] ppocr INFO: factor : 5e-05
[2024/12/09 16:00:51] ppocr INFO: name : L2
[2024/12/09 16:00:51] ppocr INFO: PostProcess :
[2024/12/09 16:00:51] ppocr INFO: box_thresh : 0.6
[2024/12/09 16:00:51] ppocr INFO: max_candidates : 1000
[2024/12/09 16:00:51] ppocr INFO: name : DBPostProcess
[2024/12/09 16:00:51] ppocr INFO: thresh : 0.3
[2024/12/09 16:00:51] ppocr INFO: unclip_ratio : 1.5
[2024/12/09 16:00:51] ppocr INFO: Train :
[2024/12/09 16:00:51] ppocr INFO: dataset :
[2024/12/09 16:00:51] ppocr INFO: data_dir : ./train_data/icdar2015/text_localization/
[2024/12/09 16:00:51] ppocr INFO: label_file_list : ['./train_data/icdar2015/text_localization/train_icdar2015_label.txt']
[2024/12/09 16:00:51] ppocr INFO: name : SimpleDataSet
[2024/12/09 16:00:51] ppocr INFO: ratio_list : [1.0]
[2024/12/09 16:00:51] ppocr INFO: transforms :
[2024/12/09 16:00:51] ppocr INFO: DecodeImage :
[2024/12/09 16:00:51] ppocr INFO: channel_first : False
[2024/12/09 16:00:51] ppocr INFO: img_mode : BGR
[2024/12/09 16:00:51] ppocr INFO: DetLabelEncode : None
[2024/12/09 16:00:51] ppocr INFO: IaaAugment :
[2024/12/09 16:00:51] ppocr INFO: augmenter_args :
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: p : 0.5
[2024/12/09 16:00:51] ppocr INFO: type : Fliplr
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: rotate : [-10, 10]
[2024/12/09 16:00:51] ppocr INFO: type : Affine
[2024/12/09 16:00:51] ppocr INFO: args :
[2024/12/09 16:00:51] ppocr INFO: size : [0.5, 3]
[2024/12/09 16:00:51] ppocr INFO: type : Resize
[2024/12/09 16:00:51] ppocr INFO: EastRandomCropData :
[2024/12/09 16:00:51] ppocr INFO: keep_ratio : True
[2024/12/09 16:00:51] ppocr INFO: max_tries : 50
[2024/12/09 16:00:51] ppocr INFO: size : [960, 960]
[2024/12/09 16:00:51] ppocr INFO: MakeBorderMap :
[2024/12/09 16:00:51] ppocr INFO: shrink_ratio : 0.4
[2024/12/09 16:00:51] ppocr INFO: thresh_max : 0.7
[2024/12/09 16:00:51] ppocr INFO: thresh_min : 0.3
[2024/12/09 16:00:51] ppocr INFO: MakeShrinkMap :
[2024/12/09 16:00:51] ppocr INFO: min_text_size : 8
[2024/12/09 16:00:51] ppocr INFO: shrink_ratio : 0.4
[2024/12/09 16:00:51] ppocr INFO: NormalizeImage :
[2024/12/09 16:00:51] ppocr INFO: mean : [0.485, 0.456, 0.406]
[2024/12/09 16:00:51] ppocr INFO: order : hwc
[2024/12/09 16:00:51] ppocr INFO: scale : 1./255.
[2024/12/09 16:00:51] ppocr INFO: std : [0.229, 0.224, 0.225]
[2024/12/09 16:00:51] ppocr INFO: ToCHWImage : None
[2024/12/09 16:00:51] ppocr INFO: KeepKeys :
[2024/12/09 16:00:51] ppocr INFO: keep_keys : ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask']
[2024/12/09 16:00:51] ppocr INFO: loader :
[2024/12/09 16:00:51] ppocr INFO: batch_size_per_card : 8
[2024/12/09 16:00:51] ppocr INFO: drop_last : False
[2024/12/09 16:00:51] ppocr INFO: num_workers : 4
[2024/12/09 16:00:51] ppocr INFO: shuffle : True
[2024/12/09 16:00:51] ppocr INFO: profiler_options : None
[2024/12/09 16:00:51] ppocr INFO: train with paddle 2.6.0 and device Place(gpu:0)
[2024/12/09 16:00:51] ppocr INFO: Initialize indexs of datasets:['E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt']
W1209 16:00:51.662034 53304 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver
API Version: 12.4, Runtime API Version: 11.7
W1209 16:00:51.667035 53304 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
[2024/12/09 16:00:52] ppocr INFO: load pretrain successful from models/ch_PP-OCRv3_det_distill_train/student
[2024/12/09 16:00:52] ppocr INFO: metric in ckpt ***************
[2024/12/09 16:00:52] ppocr INFO: is_float16:False
eval model:: 100%|██████████████████████████████████████████████████████▉| 5005/5006 [03:48<00:00, 21.88it/s]
[2024/12/09 16:04:41] ppocr INFO: metric eval ***************
[2024/12/09 16:04:41] ppocr INFO: precision:0.6304547241514874
[2024/12/09 16:04:41] ppocr INFO: recall:0.9614308553157475
[2024/12/09 16:04:41] ppocr INFO: hmean:0.7615354174910962
[2024/12/09 16:04:41] ppocr INFO: fps:42.52257374304988发现单纯使用预训练模型 student. Pdparams 在数据集上进行评估得到的 hmean 仅仅是
fine-tune
首先是进行 fine-tune :
在使用预训练模型进行fine-tune时,需要设置如下11个字段
- Global.pretrained_model: 指向PP-OCRv3文本检测预训练模型地址
- Global.eval_batch_step: 模型多少step评估一次,这里设为从第0个step开始没隔772个step评估一次,772为一个epoch总的step数。
- Optimizer.lr.name: 学习率衰减器设为常量 Cosine
- Optimizer.lr.learning_rate: 学习率设为之前的0.05倍
- Optimizer.lr.warmup_epoch: warmup_epoch设为0
- Train.dataset.data_dir:指向训练集图片存放目录
- Train.dataset.label_file_list:指向训练集标注文件
- Train.loader.num_workers: 训练集多进程数据读取的进程数,在aistudio中需要设为1
- Eval.dataset.data_dir:指向验证集图片存放目录
- Eval.dataset.label_file_list:指向验证集标注文件
- Eval.loader.num_workers: 验证集多进程数据读取的进程数,在aistudio中需要设为0
具体使用代码如下:
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams Global.save_model_dir=output/CCPD/det/ Global.eval_batch_step="[0, 772]" Optimizer.lr.name=Cosine Optimizer.lr.learning_rate=0.0005 Train.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Train.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/train/det.txt] Train.loader.num_workers=1 Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt] Eval.loader.num_workers=0验证训练出来的模型
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.checkpoints=output/CCPD/det/best_accuracy.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt]验证结果:
eval model:: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 5005/5006 [04:07<00:00, 20.25it/s]
[2024/12/15 14:58:21] ppocr INFO: metric eval ***************
[2024/12/15 14:58:21] ppocr INFO: precision:0.9951534733441034
[2024/12/15 14:58:21] ppocr INFO: recall:0.9848121502797762
[2024/12/15 14:58:21] ppocr INFO: hmean:0.9899558055443953
[2024/12/15 14:58:21] ppocr INFO: fps:46.73690379941893量化
为了在端侧设备上进行部署,我们还需要对模型进行量化以提升模型的运行速度并降低模型体积。
量化跑不动,不知道为什么,速度特别慢
这里放弃了。
问下老师,具体什么原因?
模型导出
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams Global.save_inference_dir=output/det/infer文字识别 👇
文字识别方面的配置文件用的是 ch_PP-OCRv3_rec.yml
ch_PP-OCRv3_rec.yml 配置文件详细
Global:
debug: false
use_gpu: true
epoch_num: 500
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/rec_ppocr_v3
save_epoch_step: 3
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR_LCNet
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
last_pool_kernel_size: [2, 2]
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- SARLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
ext_op_transform_idx: 1
label_file_list:
- ./train_data/train_list.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 128
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data
label_file_list:
- ./train_data/val_list.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4这一部分后续会换掉,MobileNetV1 Enhance 并没有找到具体的使用方法。
大概率会换成 ch_PP-OCRv4_rec.yml
接下里是基本流程:
提取 student 模型
import paddle
# 加载预训练模型
all_params = paddle.load("models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
# 查看权重参数的keys
# 学生模型的权重提取
s_params = {
key[len("Student.") :]: all_params[key] for key in all_params if "Student." in key
}
# 查看学生模型权重参数的keys
# 保存
paddle.save(s_params, "models/ch_PP-OCRv3_rec_train/student.pdparams")显示验证 student 模型
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR
Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/rec.txt]发现 acc 结果为 0 所以,需要调优。
直接开始训练:
参数选择
1. Global.pretrained_model: 指向PP-OCRv3文本识别预训练模型地址
2. Global.eval_batch_step: 模型多少step评估一次,这里设为从第0个step开始没隔45个step评估一次,45为一个epoch总的step数。
3. Optimizer.lr.name: 学习率衰减器设为常量 Const
4. Optimizer.lr.learning_rate: 学习率设为之前的0.05倍
5. Optimizer.lr.warmup_epoch: warmup_epoch设为0
6. Train.dataset.data_dir:指向训练集图片存放目录
7. Train.dataset.label_file_list:指向训练集标注文件
8. Train.loader.num_workers: 训练集多进程数据读取的进程数,在aistudio中需要设为1
9. Train.loader.batch_size_per_card: 训练时每张卡的图片数,这里设为64
10. Eval.dataset.data_dir:指向验证集图片存放目录
11. Eval.dataset.label_file_list:指向验证集标注文件
12. Eval.loader.num_workers: 验证集多进程数据读取的进程数,在aistudio中需要设为0
13. Eval.loader.batch_size_per_card: 验证时每张卡的图片数,这里设为64开始训练
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams Global.save_model_dir=output/CCPD/rec/ Global.eval_batch_step="[0, 30]" Optimizer.lr.learning_rate=0.0005 Train.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR Train.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/train/rec.txt] Train.loader.batch_size_per_card=64 Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/rec.txt] Eval.loader.batch_size_per_card=64模型导出
& E:/SOFTWARE/ANACONDA/envs/Paddle/python.exe tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR
Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/rec.txt]进行评估模型
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams Eval.dataset.data_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR Eval.dataset.label_file_list=[E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/rec.txt]得到的结果不错
[2024/12/13 18:55:11] ppocr INFO: metric eval ***************
[2024/12/13 18:55:11] ppocr INFO: acc:0.9541266006527913
[2024/12/13 18:55:11] ppocr INFO: norm_edit_dis:0.9866146946493206
[2024/12/13 18:55:11] ppocr INFO: fps:1097.4265973812564串联推理 👇
检测模型和识别模型分别fine-tune并导出为inference模型之后,可以使用如下命令进行端到端推理并对结果进行可视化。
使用两个模型进行推理
python tools/infer/predict_system.py --det_model_dir=output/CCPD/det/infer --rec_model_dir=output/CCPD/rec/infer --det_limit_side_len=736 --det_limit_type=min --image_dir=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/test --draw_img_save_dir=infer/fine-tune --use_dilation=true转换label并计算指标
转换label:
python tools/end2end/convert_ppocr_label.py --mode=gt --label_path=E:/LEARN/Project-all/AI/PaddleOCR-main/Data/CCPD2020/ccpd_green/PPOCR/test/det.txt --save_folder=end2end/gt计算指标:
python tools/end2end/eval_end2end.py end2end/gt/test/ end2end/fine-tune计算结果:
Start testing...
Hit, dt_count, gt_count 4538 4931 5006
Character_acc: 95.83%
Avg_edit_dist_field: 0.33
Avg_edit_dist_img: 0.33
Precision: 92.03%
Recall: 90.65%
Fmeasure: 91.34% 王海平
王海平